
什么是LLMs#
本篇内容会多次更正属于早起学习笔记,内容来源于互联网
LLMs(Large Language Models,大型语言模型)是一个广泛的术语,指的是任何规模巨大的语言模型,能够处理自然语言理解、生成、翻译等任务。它们可以有不同的架构和训练目标。典型的 LLMs 包括 GPT 系列、BERT、T5 等。这些模型通常训练在大规模数据集上,拥有数亿到数千亿的参数,支持复杂的语言任务。
一般来说,LLM模型主要由两个块组成:
编码器(左侧):编码器接收输入并构建其表示形式(特征)。这意味着该模型被优化为从输入中获取理解(比如输入文本判断这段话是高兴还是难受)。
解码器(右侧):解码器使用编码器的表示形式(特征)以及其他输入来生成目标序列。这意味着该模型被优化用于生成输出。
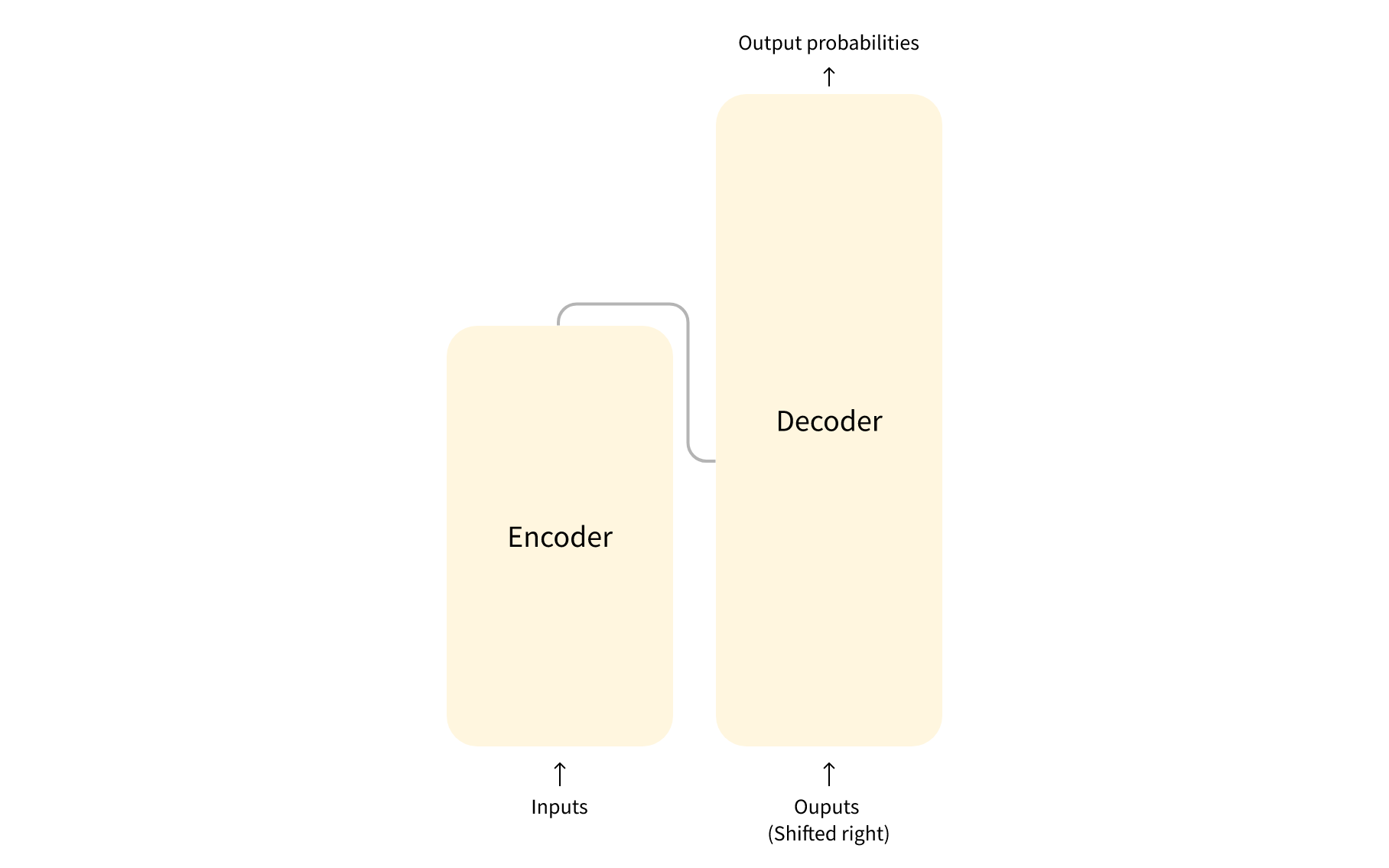
这些部分都可以根据任务独立使用:
Encoder-only models:适用于需要理解输入的任务,例如句子分类和命名实体识别。
Decoder-only models:适用于生成性任务,如文本生成。
Encoder-decoder models or sequence-to-sequence models:适用于需要输入的生成性任务,例如翻译或摘要。
LLAMA属于Decoder-only models,只有decoder层。