
Mask机制#
Decoder内部多头注意力机制中的一个特别的机制——Mask(掩膜)机制。
Mask机制经常被用于NLP任务中,按照作用总体来说可以分成两类:
用于处理非定长序列的padding mask(非官方命名);
用于防止标签泄露的sequence mask(非官方命名)。
padding mask#
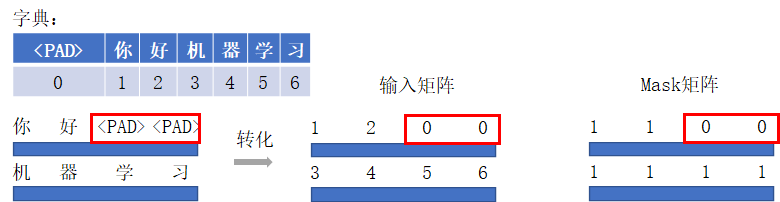
在NLP任务中,文本通常是不定长的,所以在输入一个样本长短不一的batch到网络前,要对batch中的样本进行truncating截断/padding补齐操作,以便能形成一个张量的形式输入网络,如下图所示。对于一个batch中过长的样本,进行截断操作,而对于一个长度不足的样本,往往采用特殊字符”<PAD>”进行padding(也可以是其他特殊字符,但是pad的字符要统一)。Mask矩阵中可以用1表示有效字,0代表无效字(也可以用True/False)。
sequence mask#
sequence mask有各种各样的形式和设计,最常见的应用场景是在需要一个词预测下一个词的时候,如果用self-attention或者是其他同时使用上下文信息的机制,会导致模型”提前看到“待预测的内容,这显然不行,所以为了不泄露要预测的标签信息,就需要mask来“遮盖”它。如下图所示,这也是Transformer中Decoder的Masked Multi-Head self-attention使用的Mask机制。

除了在decoder部分加入mask防止标签泄露以外,还有模型利用这种填空机制帮助模型学的更好,比如说BERT和ERNIE模型中利用到的Masked LM(MLM)。(注意:BERT模型只有Transformer的Encoder层,是可以学习上下文信息的)