
堆叠多层#
由于我们传入的\(X\)经过自注意机制后最终会得到\(r_1\),这个\(r_1\)也是一个向量,我们就可以依旧使用上面的方式进行堆叠相同的方式进行处理,这样可以使特征更明显
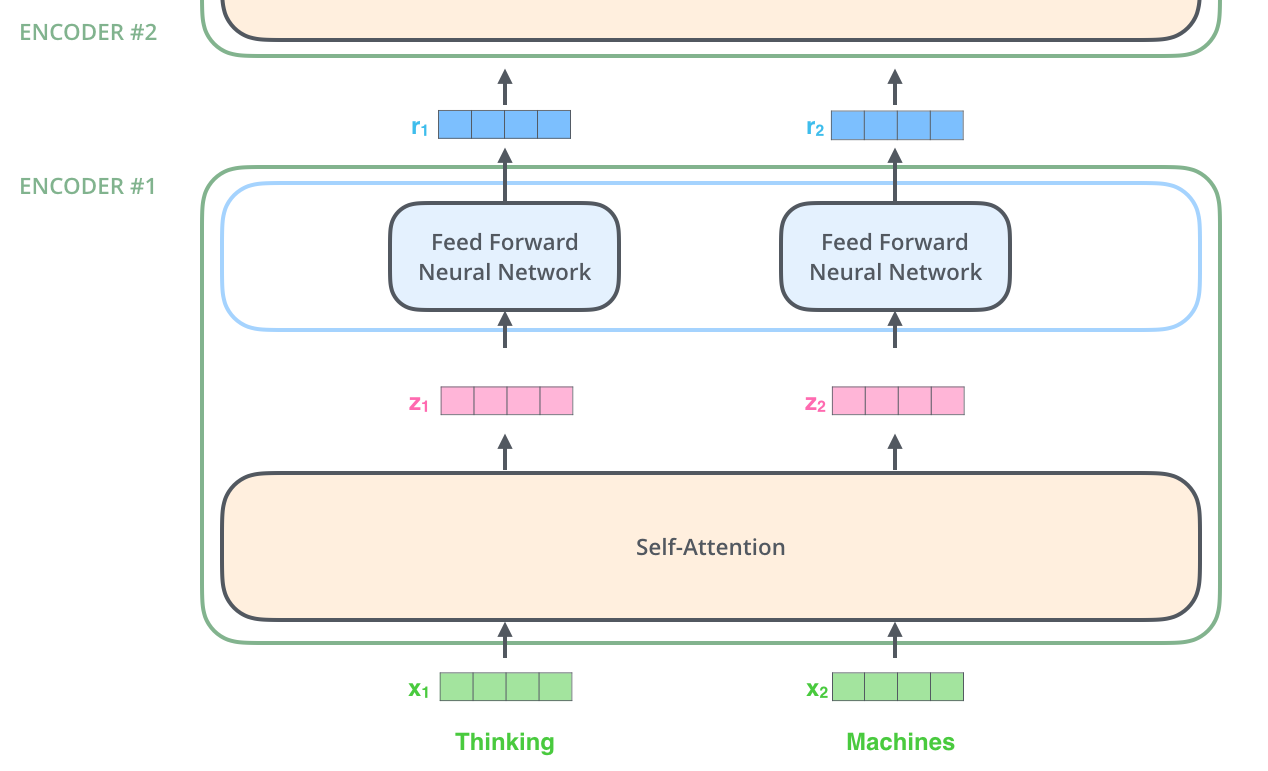
如果考虑上面两个堆叠在一起就是这样的
![]()
The Decoder Side 解码器端#
编码器首先处理输入序列,顶部编码器的输出被转换为一组注意力向量\(K\)和\(V\),给到解码器后通过与解码器中的\(Q\)结合运算出结果
以下步骤重复该过程,直到到达表示变压器解码器已完成其输出的特殊符号。
Linear and Softmax#
解码器堆栈输出浮点数向量。我们如何把它变成一个词?这就是最后一个 Linear 层的工作,后面是 Softmax 层
![]()
参考文章#
https://zhuanlan.zhihu.com/p/631463712
https://blog.csdn.net/m0_48923489/article/details/136829740
https://www.zhaokangkang.com/article/6843fe1d-f846-4eae-9fd1-cf10fdfb5d15