使用块的网络(VGG)#
虽然AlexNet证明深层神经网络卓有成效,但它没有提供一个通用的模板来指导后续的研究人员设计新的网络。 在下面的几个章节中,我们将介绍一些常用于设计深层神经网络的启发式概念。
使用块的想法首先出现在牛津大学的视觉几何组(visual geometry group)的VGG网络中。通过使用循环和子程序,可以很容易地在任何现代深度学习框架的代码中实现这些重复的架构。
VGG块#
核心思想就是VGG块
经典卷积神经网络的基本组成部分是下面的这个序列:
带填充以保持分辨率的卷积层;
非线性激活函数,如ReLU;
汇聚层,如最大汇聚层。
而一个VGG块与之类似,由一系列卷积层组成,后面再加上用于空间下采样的最大汇聚层。在最初的VGG论文中,作者使用了带有\(3\times3\)卷积核、填充为1(保持高度和宽度)的卷积层,和带有\(2 \times 2\)汇聚窗口、步幅为2(每个块后的分辨率减半)的最大汇聚层。在下面的代码中,我们定义了一个名为vgg_block的函数来实现一个VGG块。
该函数有三个参数,分别对应于卷积层的数量num_convs、输入通道的数量in_channels
和输出通道的数量out_channels.
import torch
from torch import nn
from d2l import torch as d2l
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*layers)
VGG网络#
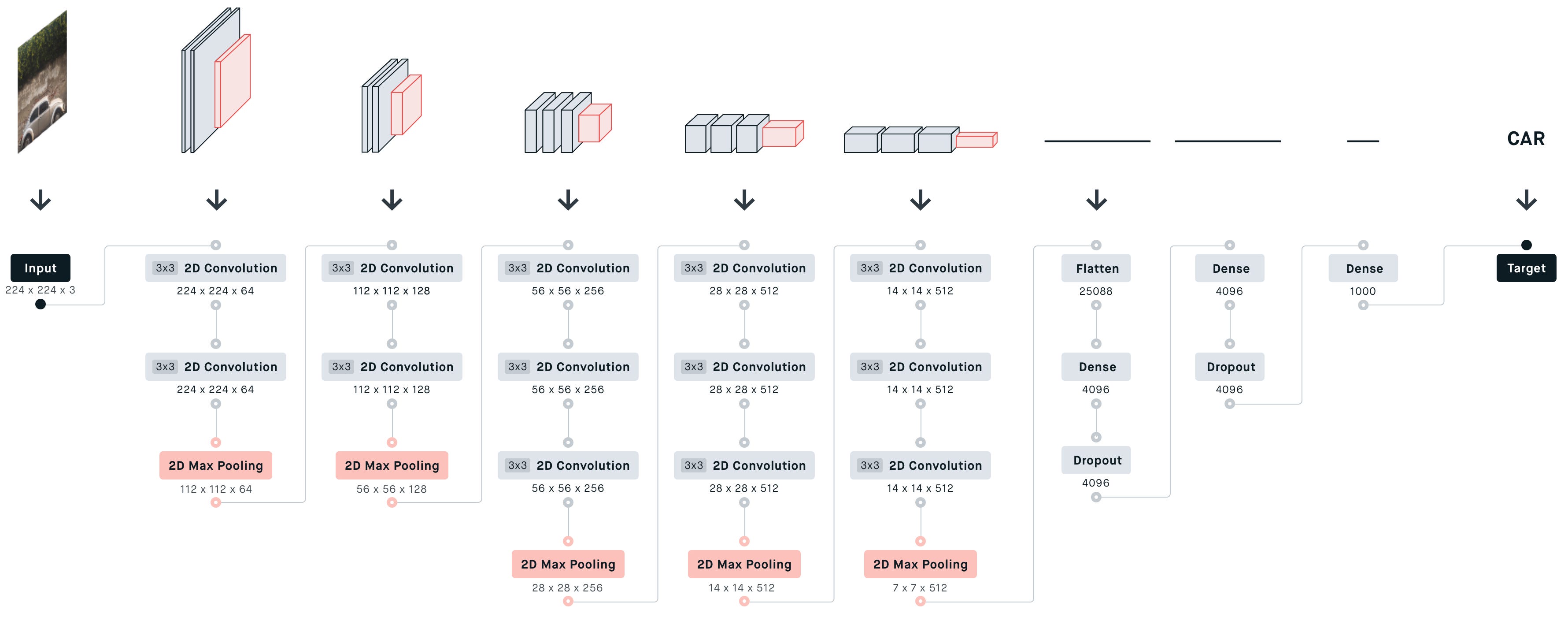
与AlexNet、LeNet一样,VGG网络可以分为两部分:第一部分主要由卷积层和汇聚层组成,第二部分由全连接层组成。如下图中所示。

VGG神经网络连接的几个VGG块(在vgg_block函数中定义)。其中有超参数变量conv_arch。该变量指定了每个VGG块里卷积层个数和输出通道数。全连接模块则与AlexNet中的相同。
原始VGG网络有5个卷积块,其中前两个块各有一个卷积层,后三个块各包含两个卷积层。 第一个模块有64个输出通道,每个后续模块将输出通道数量翻倍,直到该数字达到512。由于该网络使用8个卷积层和3个全连接层,因此它通常被称为VGG-11。
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
下面的代码实现了VGG-11。可以通过在conv_arch上执行for循环来简单实现。
def vgg(conv_arch):
conv_blks = []
in_channels = 1
# 卷积层部分
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
# 全连接层部分
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10))
net = vgg(conv_arch)
接下来,我们将构建一个高度和宽度为224的单通道数据样本,以观察每个层输出的形状。
X = torch.randn(size=(1, 1, 224, 224))
for blk in net:
X = blk(X)
print(blk.__class__.__name__,'output shape:\t',X.shape)
Sequential output shape: torch.Size([1, 64, 112, 112])
Sequential output shape: torch.Size([1, 128, 56, 56])
Sequential output shape: torch.Size([1, 256, 28, 28])
Sequential output shape: torch.Size([1, 512, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
Flatten output shape: torch.Size([1, 25088])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 10])
正如从代码中所看到的,我们在每个块的高度和宽度减半,最终高度和宽度都为7。最后再展平表示,送入全连接层处理。
训练模型#
由于VGG-11比AlexNet计算量更大,因此我们构建了一个通道数较少的网络,足够用于训练Fashion-MNIST数据集。
ratio = 4
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch)
除了使用略高的学习率外,模型训练过程与AlexNet类似。
#train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=128, resize=224)
#下载模型使用
import os
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms,datasets
import matplotlib.pyplot as plt
image_size = 224
data_transform = transforms.Compose([
#transforms.ToPILImage(), # 将torch.Tensor或numpy.ndarray类型图像转为PIL.Image类型图像。这段里面可以移除transforms.ToPILImage(),因为 FashionMNIST 数据集已经是 PIL.Image 类型
transforms.Resize(image_size),#按给定尺寸对图像进行缩放
transforms.ToTensor() #将PIL.Image或numpy.ndarray类型图像转为torch.Tensor类型图像
])
# train表示是否是训练集,download表示是否需要下载,transform表示是否需要进行数据变换
train_data = datasets.FashionMNIST(root='../raw/data/', train=True, download=True, transform=data_transform)
test_data = datasets.FashionMNIST(root='../raw/data/', train=False, download=True, transform=data_transform)
batch_size = 128
num_workers = 0 #mac 不知道为什么变为4也报错 # 对于Windows用户,这里应设置为0,否则会出现多线程错误
# DataLoader是一个用于生成batch数据的迭代器,可以设置batch_size、shuffle、num_workers等参数
#batch_size是指每个批次中包含的样本数量。shuffle=True表示在每个epoch开始时,将训练数据集打乱顺序,以增加模型的泛化能力。num_workers是指用于数据加载的线程数量,可以加快数据加载的速度。drop_last=True表示如果训练数据集的样本数量不能被batch_size整除,最后一个不完整的批次将被丢弃。
train_iter = DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True)
test_iter = DataLoader(test_data, batch_size=batch_size, shuffle=False, num_workers=num_workers)
lr, num_epochs= 0.05, 10
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
loss 0.172, train acc 0.936, test acc 0.923
1241.4 examples/sec on cuda:0

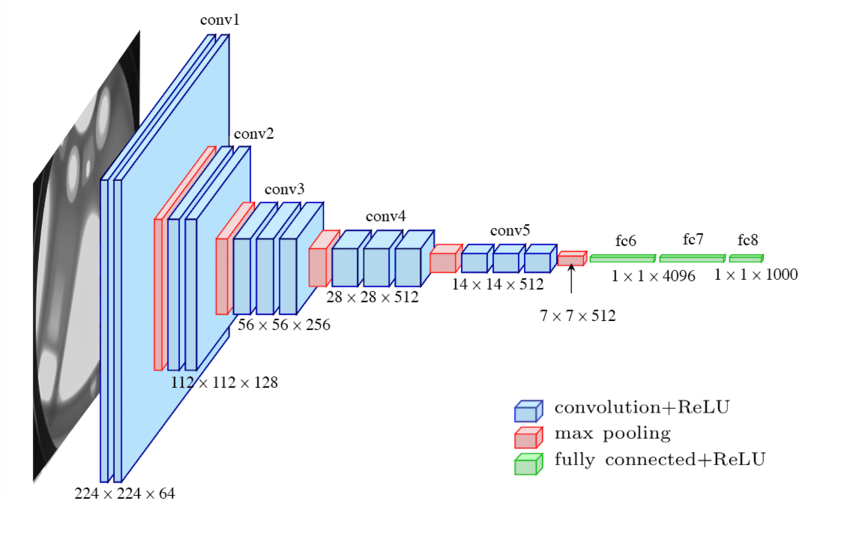
VGG16#
下图介绍了VGG整个网络的训练过程
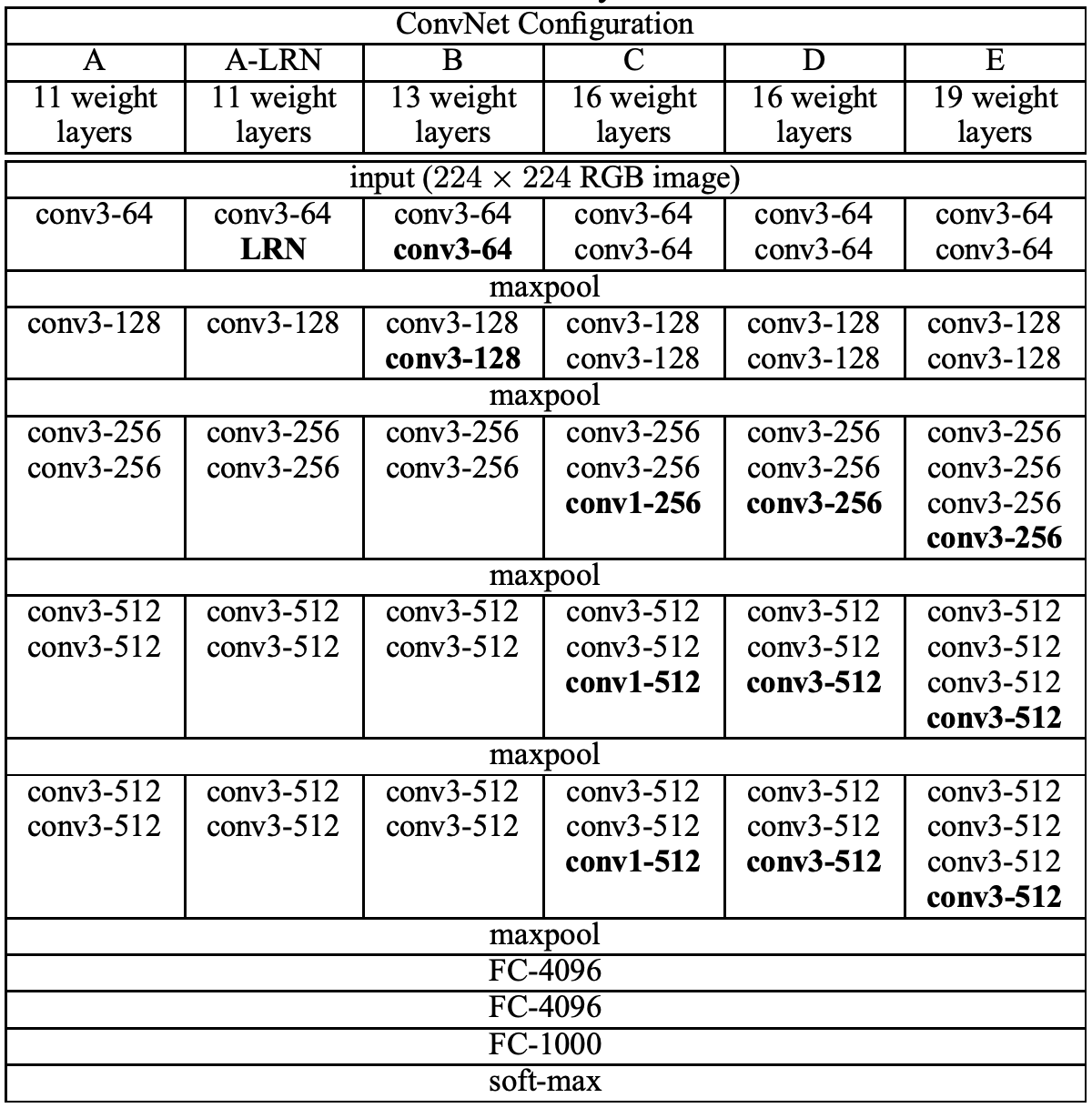
VGG 配置#
VGG 网络有五种配置,分别为 A 到 E。配置的深度从左 (A) 到右 (B) 增加,并添加了更多层。下表描述了所有潜在的网络架构