
梯度下降#
想象一下,你是一个勇敢的寻宝者,被空投到了一座连绵不绝的大山上。你的任务是找到这座山脉的最低点,因为传说中宝藏就埋在那里。
但有一个问题:山上起了大雾,你看不见整个山的全貌,能见度只有你脚下的一小块地方。
你该怎么办?
一个非常聪明的策略是:
环顾四周:在你当前的位置,感受一下哪个方向是下坡最陡峭的。
迈出一步:朝着那个最陡的下坡方向,小心地迈出一步。
重复:到达新位置后,再次环顾四周,找到新的最陡下坡方向,再迈一步。
一直这样重复下去,虽然你每次都只看脚下,但最终你很有可能会走到山谷的最低点,找到宝藏!
恭喜你,你刚刚已经理解了梯度下降(Gradient Descent)的核心思想!
现在,我们把这个故事和机器学习联系起来:
那座山 (The Mountain):就是机器学习里的 损失函数 (Loss Function)。它衡量了你的模型有多“差”。山越高,代表模型的预测错误越大;山越低,代表模型越好。
你的位置 (Your Position):就是模型的 参数 (Parameters),比如我们常说的
w(权重) 和b(偏置)。调整这些参数,就相当于你在山上移动。宝藏 (The Treasure):就是损失函数的 最小值,也就是模型表现最好的那一组参数
w和b。寻找最陡的下坡方向:这个“方向”就是 梯度 (Gradient)。梯度会指向山上坡度最陡峭的上坡方向,那么它的反方向(负梯度)自然就是最陡的下坡方向。
你迈出的那一步的大小:这就是 学习率 (Learning Rate)。步子迈得太大,可能会直接跨过最低点,跑到对面山坡上去了。步子太小,下山会非常非常慢。所以这是一个需要小心调整的超参数。
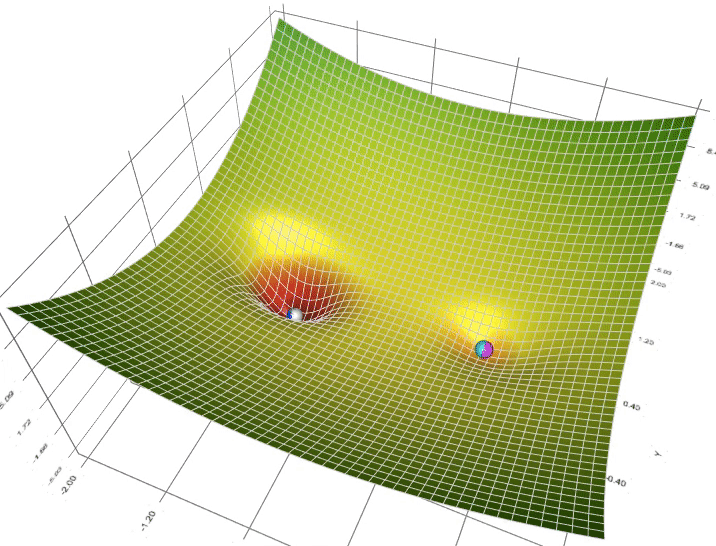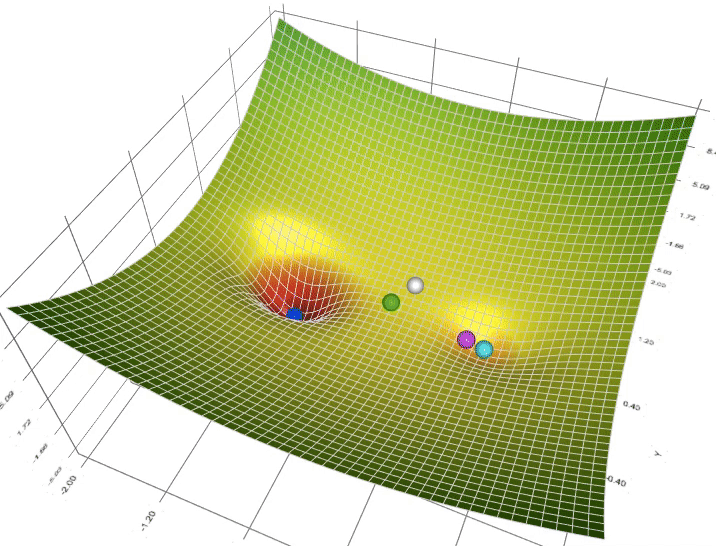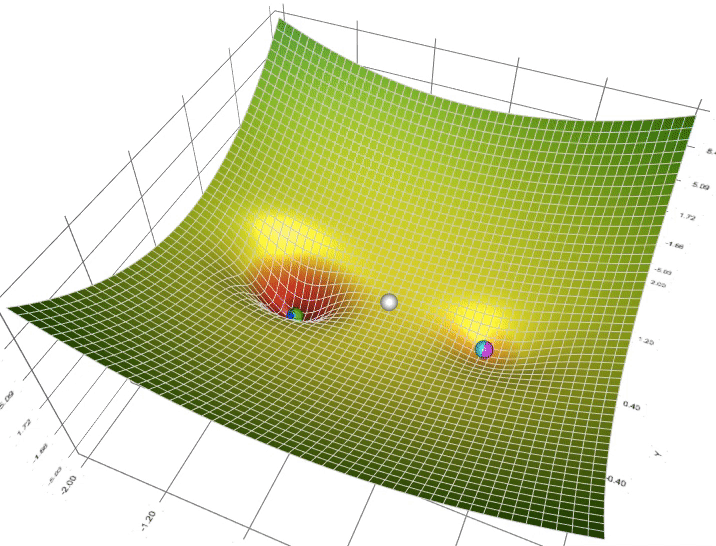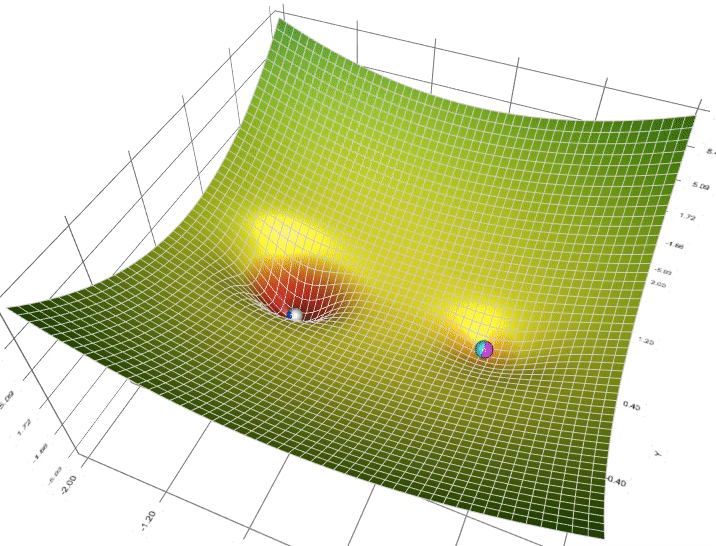
梯度下降的流程总结
目标:找到一组参数 (
w,b),让损失函数 (Loss) 最小。步骤:
随机初始化一组参数 (
w,b)。计算当前参数下的损失。
计算损失函数关于每个参数的梯度(也就是“坡度”)。
沿着梯度相反的方向,更新参数(
新参数 = 旧参数 - 学习率 * 梯度)。重复 2-4 步,直到损失不再明显下降,我们就找到了“宝藏”!
用 PyTorch 来一场真实的“下山寻宝”#
现在我们用代码来实现这个过程。假设我们要解决一个超级简单的问题:我们有一堆数据 X 和 y,并且我们知道它们的关系大致是 y = 2 * X + 1。我们假装不知道 2 和 1 这两个数字,让模型自己去学。
第一幕:手动实现梯度下降(帮你理解原理)#
这部分代码会帮你理解底层发生了什么。
import torch
# 1. 准备数据 (我们的“地图”和真实宝藏位置)
X = torch.tensor([[1.0], [2.0], [3.0], [4.0]], dtype=torch.float32)
# 真实的 y = 2 * X + 1
y = torch.tensor([[3.0], [5.0], [7.0], [9.0]], dtype=torch.float32)
# 2. 随机初始化参数 (随机把你空投到山上的某个位置)
# 我们需要找到 w 和 b,让模型 y_pred = w * X + b 尽可能接近真实的 y
# requires_grad=True 告诉 PyTorch: “请帮我追踪这两个变量的梯度!”
w = torch.tensor([[0.0]], requires_grad=True, dtype=torch.float32)
b = torch.tensor([[0.0]], requires_grad=True, dtype=torch.float32)
# 3. 设置学习率 (决定你每一步迈多大)
learning_rate = 0.01
print("开始寻宝!起点 w={}, b={}".format(w.item(), b.item()))
# 4. 开始下山!(迭代训练)
for epoch in range(100):
# a. 向前走,用当前的 w, b 预测一下
# 这就是我们的模型
y_pred = X @ w + b # @ 是矩阵乘法
# b. 看看离宝藏还有多远 (计算损失)
# 我们用均方误差 (MSE) 作为损失函数,它就像山的高度计
loss = torch.mean((y_pred - y) ** 2)
# c. 关键一步:计算梯度 (环顾四周,找到最陡的下坡方向)
# PyTorch 的魔法来了!loss.backward() 会自动计算损失对 w 和 b 的梯度
loss.backward()
# d. 更新参数 (朝着下坡方向迈出一步)
# 使用 torch.no_grad() 是因为我们不希望参数更新这个操作本身被追踪梯度
with torch.no_grad():
w -= learning_rate * w.grad
b -= learning_rate * b.grad
# e. 清空梯度!(非常重要)
# 梯度是会累加的,每次循环前都要清零,否则就像你闭着眼睛凭记忆走路,会走偏
w.grad.zero_()
b.grad.zero_()
if (epoch + 1) % 10 == 0:
print("第 {} 步: 损失(山的高度) = {:.4f}, w = {:.3f}, b = {:.3f}".format(
epoch + 1, loss.item(), w.item(), b.item()
))
print("\n寻宝结束!找到的 w ≈ {:.3f}, b ≈ {:.3f}".format(w.item(), b.item()))
开始寻宝!起点 w=0.0, b=0.0
第 10 步: 损失(山的高度) = 1.5412, w = 1.757, b = 0.607
第 20 步: 损失(山的高度) = 0.0518, w = 2.038, b = 0.712
第 30 步: 损失(山的高度) = 0.0126, w = 2.080, b = 0.735
第 40 步: 损失(山的高度) = 0.0109, w = 2.085, b = 0.745
第 50 步: 损失(山的高度) = 0.0102, w = 2.084, b = 0.753
第 60 步: 损失(山的高度) = 0.0096, w = 2.081, b = 0.761
第 70 步: 损失(山的高度) = 0.0091, w = 2.079, b = 0.768
第 80 步: 损失(山的高度) = 0.0085, w = 2.077, b = 0.775
第 90 步: 损失(山的高度) = 0.0080, w = 2.074, b = 0.781
第 100 步: 损失(山的高度) = 0.0076, w = 2.072, b = 0.788
寻宝结束!找到的 w ≈ 2.072, b ≈ 0.788
代码解释:
requires_grad=True:这是 PyTorch 自动求导(autograd)引擎的开关。只有打开它,loss.backward()才能计算出这个张量(w和b)的梯度。loss.backward():这是最神奇的一步。它会像多米诺骨牌一样,从loss开始反向传播,计算出计算图上所有requires_grad=True的张量的梯度,并把结果存放在它们的.grad属性里。w.grad和b.grad:这就是loss.backward()计算出的梯度值。w.grad.zero_():每次更新完参数后,必须清空梯度。 因为PyTorch默认会把梯度累加起来,如果不清零,下一次计算的梯度就会被加到上一次的结果上,导致更新方向错误。
第二幕:使用 PyTorch 的优化器(更简洁的标准方式)#
手动更新参数虽然能帮我们理解原理,但在真实项目中,模型可能有成千上万个参数,手动一个个更新太麻烦了。PyTorch 提供了一个专业的“登山向导”——优化器 (Optimizer)。
优化器会帮我们自动完成“更新参数”和“清空梯度”这两件杂事。
import torch
import torch.nn as nn
import torch.optim as optim
# 1. 准备数据 (和之前一样)
X = torch.tensor([[1.0], [2.0], [3.0], [4.0]], dtype=torch.float32)
y = torch.tensor([[3.0], [5.0], [7.0], [9.0]], dtype=torch.float32)
# 2. 定义模型、损失函数和优化器
# nn.Linear(1, 1) 是一个线性层,它内部自动包含了 w 和 b,我们不用自己定义了
# 1 个输入特征,1 个输出特征
model = nn.Linear(1, 1)
# PyTorch 内置的均方误差损失
loss_fn = nn.MSELoss()
# 定义我们的“登山向导”——优化器
# 我们使用 SGD (随机梯度下降),它是梯度下降的一种变体
# 把模型的参数 (model.parameters()) 和学习率告诉它
learning_rate = 0.01
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
print("开始寻宝(专业向导版)!")
# 3. 开始下山!(迭代训练)
for epoch in range(100):
# a. 预测
y_pred = model(X)
# b. 计算损失
loss = loss_fn(y_pred, y)
# c. 清空旧梯度 (向导帮你做)
optimizer.zero_grad()
# d. 计算新梯度 (和之前一样)
loss.backward()
# e. 更新参数 (向导帮你做)
optimizer.step()
if (epoch + 1) % 10 == 0:
# model.parameters() 返回一个生成器,我们可以从中提取 w 和 b
w, b = model.parameters()
print("第 {} 步: 损失 = {:.4f}, w = {:.3f}, b = {:.3f}".format(
epoch + 1, loss.item(), w[0][0].item(), b[0].item()
))
print("\n寻宝结束!找到的 w ≈ {:.3f}, b ≈ {:.3f}".format(
model.weight.item(), model.bias.item()
))
开始寻宝(专业向导版)!
第 10 步: 损失 = 0.5867, w = 1.902, b = 0.611
第 20 步: 损失 = 0.0308, w = 2.072, b = 0.680
第 30 步: 损失 = 0.0155, w = 2.097, b = 0.698
第 40 步: 损失 = 0.0143, w = 2.098, b = 0.708
第 50 步: 损失 = 0.0134, w = 2.096, b = 0.717
第 60 步: 损失 = 0.0126, w = 2.093, b = 0.726
第 70 步: 损失 = 0.0119, w = 2.091, b = 0.734
第 80 步: 损失 = 0.0112, w = 2.088, b = 0.742
第 90 步: 损失 = 0.0106, w = 2.085, b = 0.749
第 100 步: 损失 = 0.0099, w = 2.083, b = 0.757
寻宝结束!找到的 w ≈ 2.083, b ≈ 0.757
代码解释:
nn.Linear(1, 1):这是 PyTorch 提供的一个标准“层”。它替我们管理了w和b,我们只需要调用model(X)就可以做预测。nn.MSELoss():这是 PyTorch 提供的标准损失函数,不用我们自己手写torch.mean(...)。optim.SGD(...):我们创建了一个 SGD 优化器实例,并告诉它要管理哪些参数(model.parameters())以及学习率是多少。optimizer.zero_grad():一行代码就替代了之前所有的param.grad.zero_(),非常方便。optimizer.step():这一步会根据之前loss.backward()计算出的梯度,自动更新所有它管理的参数。它内部执行的逻辑就是w -= lr * w.grad。
总结#
梯度下降就像一个在大雾中凭感觉下山的过程:
目标:找到山谷最低点(损失函数的最小值)。
方法:在当前位置,计算梯度(最陡的上坡方向),然后朝着梯度的反方向(最陡的下坡方向)走一小步(由学习率决定大小)。
重复:不断重复这个过程,直到我们足够接近最低点。
PyTorch 的 autograd 引擎 (loss.backward()) 和 optim 模块(优化器)极大地简化了这个过程,让我们能够专注于构建模型,而不是手动进行数学计算和参数更新。
这个简单而强大的思想,是驱动今天几乎所有深度学习模型训练的核心动力。希望这个“下山寻宝”的故事能让你彻底明白梯度下降!