
6-LoRA#
大语言模型的低秩适应(LoRA, Low-Rank Adaptation of Large Language Models) 是一项大模型参数高效微调技术,其可以显著减少可训练参数的数量.
由于大模型参数量较大,直接进行全参微调需要消耗大量硬件资源,LoRA 的工作原理是将少量的新权重插入倒模型中,并且仅训练这些权重,这使得使用 LoRA 进行训练的速度更快、内存效率更高,并生成更小的模型权重.
具体来说,LoRA 它冻结了预训练模型 W 的权重,并注入可训练的秩分解矩阵 A 与 B,在微调时,只训练降维矩阵 A 和 升维矩阵 B,微调结束后,将 AB 与 W 进行叠加.
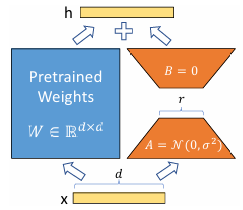
其中,用随机高斯分布进行初始化 A,用 0 矩阵初始化 B,从而保证训练开始时旁路矩阵为 0 矩阵.
具体来看,假设模型经过预训练主干的输出为 \(W_0 x\),在 LoRA 微调阶段,我们可以用如下形式对输出进行表示.
其中, \(B \in \mathbb{R}^{d \times r},A \in \mathbb{R}^{r\times k}\),r 为 LoRA 低秩矩阵的维数,\(r << min(d, k)\).
# 导入 PyTorch 核心库
import torch
# 从 PyTorch 中导入 optim (优化器) 和 nn (神经网络模块),这是构建任何神经网络模型的基础
from torch import optim, nn
LoRA Adapter#
简单的来说,LoRA 矩阵就是具有一个隐藏层的全连接网络,其挂接在主干网络边侧进行参数更新,我们来看看 MiniMind 模型是如何在主干网络外部定义 LoRA 网络结构的.
# 定义 LoRA 模块,它本身也是一个标准的 PyTorch 模块
class LoRA(nn.Module):
# 构造函数
# in_features: 原始线性层的输入维度
# out_features: 原始线性层的输出维度
# rank: LoRA 的秩 (r),这是一个关键的超参数,控制了 LoRA 矩阵的大小和表达能力
def __init__(self, in_features, out_features, rank):
super().__init__()
self.rank = rank
# 定义低秩分解矩阵 A 和 B
# 矩阵 A:一个线性层,将维度从 in_features 降低到 rank
self.A = nn.Linear(in_features, rank, bias=False)
# 矩阵 B:一个线性层,将维度从 rank 升回到 out_features
self.B = nn.Linear(rank, out_features, bias=False)
# 初始化权重,这是 LoRA 论文中提到的关键步骤
# `self.A.weight.data` 获取 A 矩阵的权重张量
# `.normal_(...)`: 使用均值为 0,标准差为 0.02 的正态分布(高斯分布)来初始化 A
self.A.weight.data.normal_(mean=0.0, std=0.02)
# `.zero_()`: 将 B 矩阵的权重全部初始化为 0
# 这样设置可以保证在训练开始时,LoRA 旁路 (B * A) 的输出为 0,
# 使得 LoRA 微调是从原始模型的性能基础上平滑开始的。
self.B.weight.data.zero_()
# LoRA 模块的前向传播
def forward(self, x):
# 计算 LoRA 旁路的输出 ΔW * x,也就是 B(A(x))
# 1. self.A(x): 输入 x 先经过 A 矩阵降维
# 2. self.B(...): 降维后的结果再经过 B 矩阵升维
return self.B(self.A(x))
可以看到,LoRA 的网络结构非常简单直观,我们接下来定义一个方法,将 LoRA 网络应用到 MiniMind 模型的特定线性层.
# 定义一个函数,用于遍历一个大模型,并自动地为符合条件的线性层添加 LoRA 适配器
def apply_lora(model, rank=16):
"""将 LoRA 模块与目标模块进行绑定"""
# `model.named_modules()`: 遍历模型中的所有模块(包括子模块),并返回它们的名称和模块本身
for name, module in model.named_modules():
# 设置添加 LoRA 的条件:
# 1. `isinstance(module, nn.Linear)`: 必须是一个线性层
# 2. `module.weight.shape[0] == module.weight.shape[1]`: 输入和输出维度必须相等(即方阵)
# 这是一种常见的简化策略,通常 Q, K, V, O 投影矩阵都符合这个条件
if isinstance(module, nn.Linear) and module.weight.shape[0] == module.weight.shape[1]:
# a. 创建一个 LoRA 实例
lora = LoRA(module.in_features, module.out_features, rank=rank).to(model.device)
# b. "猴子补丁" (Monkey Patching):动态地修改原始模块
# `setattr(module, 'lora', lora)`: 动态地给原始的线性层 `module` 添加一个新的属性 `lora`,
# 它的值就是我们刚创建的 LoRA 实例。
setattr(module, 'lora', lora)
# c. 保存原始的 forward 方法
original_forward = module.forward
# d. 定义一个新的 forward 函数
# 这个新函数会同时调用原始的 forward 和 lora 的 forward,然后将结果相加
# 这实现了公式: h = W0*x + BA*x
def forward_with_lora(x, layer1=original_forward, layer2=lora):
return layer1(x) + layer2(x)
# e. 用我们新定义的 `forward_with_lora` 替换掉原始的 `module.forward`
module.forward = forward_with_lora
print(f'apply lora on module: {name}')
我们可以声明一个小模型,对于 LoRA 的绑定进行测试.
# 定义一个简单的测试模型,用来验证 `apply_lora` 函数是否工作正常
class TestModel(nn.Module):
def __init__(self):
super().__init__()
# 定义三个线性层
self.linear1 = nn.Linear(64, 512) # 输入输出维度不同
self.linear2 = nn.Linear(512, 512) # 输入输出维度相同 (方阵) -> 符合 `apply_lora` 的条件
self.linear3 = nn.Linear(512, 64) # 输入输出维度不同
# 定义一个 `device` 属性,方便获取模型所在的设备
# `@property` 装饰器让我们可以像访问变量一样调用这个方法 (e.g., `model.device`)
@property
def device(self):
# `next(self.parameters())` 获取模型的第一个参数
# `.device` 获取该参数所在的设备
return next(self.parameters()).device
def forward(self, x):
# 定义模型的前向传播路径
out = self.linear3(self.linear2(self.linear1(x))) # 注意:原文代码有笔误 `self.linear1`,这里按正确逻辑注释
return out
按照 apply_lora 的函数逻辑,LoRA 模块会应用在主干网络中满足 input_feature == output_feature 的模块上.
# 1. 实例化我们的测试模型
test_model = TestModel()
# 2. 调用 `apply_lora` 函数,将 LoRA 适配器应用到 test_model 上
# 根据我们设定的条件,只有 `linear2` 会被添加 LoRA
apply_lora(test_model)
# 3. 打印模型结构
# 从输出中可以看到,`linear2` 模块内部现在多了一个 `lora` 子模块,证明 `apply_lora` 成功了
print(test_model)
apply lora on module: linear2
TestModel(
(linear1): Linear(in_features=64, out_features=512, bias=True)
(linear2): Linear(
in_features=512, out_features=512, bias=True
(lora): LoRA(
(A): Linear(in_features=512, out_features=16, bias=False)
(B): Linear(in_features=16, out_features=512, bias=False)
)
)
(linear3): Linear(in_features=512, out_features=64, bias=True)
)
# 删除测试模型,释放内存
del test_model
完成了 LoRA 模块在主干网络特定模块的绑定后,我们便可以冻结主干网络参数进行微调了,不过,考虑到主干网络权重在训练过程中并不会做任何参数更新,我们可以只保存 LoRA 模块的参数来节省内存,下面给出加载/保存 LoRA 权重的方法.
# 定义一个函数来加载 LoRA 权重到模型中
def load_lora(model, path):
# 1. 从磁盘加载 LoRA 权重文件
state_dict = torch.load(path, map_location=model.device)
# 2. 遍历模型的所有模块
for name, module in model.named_modules():
# 如果这个模块被添加了 lora 属性
if hasattr(module, 'lora'):
# 从加载的 state_dict 中筛选出只属于当前模块的 LoRA 权重
# 例如,从 "layers.0.attention.wq.lora.A.weight" 中提取出 "A.weight"
lora_state = {k.replace(f'{name}.lora.', ''): v for k, v in state_dict.items() if f'{name}.lora.' in k}
# 将筛选出的权重加载到对应的 lora 子模块中
module.lora.load_state_dict(lora_state)
# 定义一个函数来只保存模型中的 LoRA 权重
def save_lora(model, path):
# 1. 创建一个空的 state_dict 来存放 LoRA 权重
state_dict = {}
# 2. 遍历模型的所有模块
for name, module in model.named_modules():
# 如果这个模块被添加了 lora 属性
if hasattr(module, 'lora'):
# 获取这个 lora 子模块自己的 state_dict
# 它的键是 "A.weight", "B.weight" 等
# 我们需要给这些键加上完整的前缀,比如 "layers.0.attention.wq.lora.A.weight"
lora_state = {f'{name}.lora.{k}': v for k, v in module.lora.state_dict().items()}
# 将处理好的权重更新到我们总的 state_dict 中
state_dict.update(lora_state)
# 3. 将只包含 LoRA 权重的 state_dict 保存到磁盘
torch.save(state_dict, path)
Fine-Tuning MiniMind with LoRA#
# -------------------- 导入标准和第三方库 --------------------
# 导入 os 库,用于与操作系统交互
import os
# 导入 platform 库,用于获取系统信息
import platform
# 导入 argparse 库,用于解析命令行参数
import argparse
# 导入 random 库,用于生成随机数
import random
# 导入 time 库,用于计时
import time
# 导入 math 库,用于数学运算
import math
# 导入 warnings 库,用于控制警告信息
import warnings
# 导入 PyTorch 的分布式训练库
import torch.distributed as dist
# 导入一个上下文管理器
from contextlib import nullcontext
# 导入 PyTorch 的数据加载器和分布式采样器
from torch.utils.data import DataLoader, DistributedSampler
# -------------------- 导入 Hugging Face 和自定义模块 --------------------
# 从 transformers 库导入 AutoTokenizer 和 AutoModelForCausalLM
from transformers import AutoTokenizer, AutoModelForCausalLM
# 从我们自己的 model 文件夹中导入之前编写好的模块
from model.model import MiniMindLM # 我们的语言模型
from model.LMConfig import LMConfig # 模型配置类
# 因为 LoRA 微调的数据格式与 SFT 相同,所以我们复用 SFTDataset
from model.dataset import SFTDataset
# 设置警告过滤器,让程序忽略所有的警告信息,使输出更整洁
warnings.filterwarnings('ignore')
可选参数设置#
首先,查看训练的可选参数,这些参数在实际使用时通过解析命令行进行导入,我们用 class 进行包装.
# 使用一个 class 来模拟命令行参数,集中管理所有超参数
class args:
# 训练过程超参数
epochs: int = 1
batch_size: int = 2
learning_rate: float = 5e-4
# 硬件和精度设置
device: str = 'cuda' if torch.cuda.is_available() else 'cpu'
dtype: str = 'bfloat16'
# 日志和数据加载
wandb_project: str = 'MiniMind-Notebook'
num_workers: int = 1
# 高级训练技巧
accumulation_steps: int = 1
grad_clip: float = 1.0
warmup_iters: int = 0
log_interval: int = 1
# 分布式训练相关
local_rank: int = 1
# 模型结构超参数
dim: int = 512
n_layers: int = 2
max_seq_len: int = 512
use_moe: bool = False
# LoRA 微调相关参数
data_path: str = '../raw/data/Minimind/toydata/lora_data.jsonl' # 数据集路径指向 LoRA 的特定数据
lora_name: str = 'lora_identity' # 定义保存的 LoRA 权重文件的名称
# 打印出 `args` 中设置的 `device`,确认程序将在哪个设备上运行(CPU 或 GPU)
print(f'查看工作设备 {args.device}')
查看工作设备 cuda
接下来,我们对分词器、MiniMindLM 和数据迭代器执行初始化.
# 定义一个函数来封装 LoRA 微调前的模型初始化过程
def init_model(lm_config):
# 1. 加载分词器
tokenizer = AutoTokenizer.from_pretrained('../raw/data/Minimind/model/minimind_tokenizer')
# 2. 根据配置,创建一个与基础模型结构完全相同的模型
model = MiniMindLM(lm_config)
# --- 关键步骤:加载基础模型权重 ---
# LoRA 微调是在一个已经训练好的模型基础上进行的
# 因此,在真实流程中,这里需要加载一个预训练好或 SFT/DPO 过的模型权重
# 下面的代码被注释掉了,但展示了这个过程
moe_path = '_moe' if lm_config.use_moe else ''
# a. 定义基础模型权重文件的路径 (例如,一个经过 DPO 训练的模型)
# ckp = f'./out/rlhf_{lm_config.dim}{moe_path}.pth'
# b. 加载权重文件
# state_dict = torch.load(ckp, map_location=args.device)
# c. 将权重加载到模型中
# model.load_state_dict(state_dict, strict=False)
# ---------------------------------
# 3. 将模型移动到指定设备并返回
return model.to(args.device), tokenizer
# --- 1. 创建模型配置 ---
lm_config = LMConfig(dim=args.dim, n_layers=args.n_layers, max_seq_len=args.max_seq_len, use_moe=args.use_moe)
# --- 2. 初始化基础模型和分词器 ---
model, tokenizer = init_model(lm_config)
# --- 3. 为模型注入 LoRA 适配器 ---
# 调用 `apply_lora` 函数,动态地为模型中的特定线性层添加 LoRA 模块
apply_lora(model)
# --- 4. 初始化数据集 ---
# LoRA 微调数据格式与 SFT 相同,所以我们复用 `SFTDataset` 来加载 `lora_data.jsonl` 文件
train_ds = SFTDataset(args.data_path, tokenizer, max_length=lm_config.max_seq_len)
# --- 5. 初始化数据加载器 (DataLoader) ---
train_loader = DataLoader(
train_ds,
batch_size=args.batch_size,
pin_memory=True,
drop_last=False,
shuffle=False,
num_workers=args.num_workers,
)
# --- 6. 打印确认信息 ---
print(f'模型位于设备:{model.device}, 词表长度:{tokenizer.vocab_size}, DataLoader:{train_loader}')
apply lora on module: layers.0.attention.wq
apply lora on module: layers.0.attention.wo
apply lora on module: layers.1.attention.wq
apply lora on module: layers.1.attention.wo
模型位于设备:cuda:0, 词表长度:6400, DataLoader:<torch.utils.data.dataloader.DataLoader object at 0x000001F14AF3E1A0>
可以看到,LoRA 模块挂接在 Attention Block 的 Query 与 Output 线性层上,下面查看 LoRA 微调下可学习参数的占比:
# 计算模型的总参数量
total_params = sum(p.numel() for p in model.parameters())
# 只计算 LoRA 相关的参数量
# 通过名称筛选出所有属于 LoRA 模块的参数 (`lora` in name)
lora_params_count = sum(p.numel() for name, p in model.named_parameters() if 'lora' in name)
print(f"LLM 总参数量: {total_params}")
print(f"LoRA 参数量: {lora_params_count}")
# 计算 LoRA 参数占总参数的百分比,展示 LoRA 的参数高效性
print(f"LoRA 参数占比: {lora_params_count / total_params * 100:.2f}%")
LLM 总参数量: 8980992
LoRA 参数量: 65536
LoRA 参数占比: 0.73%
接下来,冻结 MiniMindLM 主干网络的参数,做好 LoRA 微调准备.
# --- 冻结主干网络,只训练 LoRA 参数 ---
# 遍历模型的所有参数及其名称
for name, param in model.named_parameters():
# 如果参数的名称中不包含 'lora',说明它属于原始的基础模型
if 'lora' not in name:
# 将其 `requires_grad` 属性设置为 False,冻结该参数,使其在训练中不被更新
param.requires_grad = False
# 创建一个列表,用于收集所有可训练的参数(也就是 LoRA 的参数)
lora_params = []
# 再次遍历所有参数
for name, param in model.named_parameters():
# 如果参数名称中包含 'lora'
if 'lora' in name:
# 将该参数添加到 lora_params 列表中
lora_params.append(param)
# 这个 `lora_params` 列表稍后会传递给优化器
启动训练#
接下来,我们定义 MiniMind LoRA 微调所使用的优化器,损失函数和学习率调度,并进行一轮简单的训练.
# 1. 定义学习率调度函数 (余弦退火)
def get_lr(current_step, total_steps, lr):
return lr / 10 + 0.5 * lr * (1 + math.cos(math.pi * current_step / total_steps))
# 2. 设置混合精度训练的梯度缩放器 (Scaler)
scaler = torch.cuda.amp.GradScaler(enabled=(args.dtype in ['float16', 'bfloat16']))
# 3. 初始化优化器 (AdamW)
# 关键之处:我们将 `lora_params` 列表(只包含 LoRA 参数)传递给优化器
# 这样,优化器就只会更新 LoRA 适配器的权重,而忽略被冻结的基础模型权重
optimizer = optim.AdamW(lora_params, lr=args.learning_rate)
# 4. 设置自动混合精度上下文 (Autocast)
device_type = "cuda" if "cuda" in args.device else "cpu"
ctx = nullcontext() if device_type == "cpu" else torch.cuda.amp.autocast()
接下来,我们来看训练函数.
# 定义 LoRA 微调的训练 epoch 函数
def train_epoch(epoch):
loss_fct = nn.CrossEntropyLoss(reduction='none')
start_time = time.time()
# 遍历 DataLoader
for step, (X, Y, loss_mask) in enumerate(train_loader):
# 数据移动到设备
X = X.to(args.device)
Y = Y.to(args.device)
loss_mask = loss_mask.to(args.device)
# 更新学习率
lr = get_lr(epoch * iter_per_epoch + step, args.epochs * iter_per_epoch, args.learning_rate)
for param_group in optimizer.param_groups:
param_group['lr'] = lr
# 前向传播和损失计算 (与 SFT 完全相同)
with ctx:
res = model(X)
loss = loss_fct(res.logits.view(-1, res.logits.size(-1)), Y.view(-1)).view(Y.size())
# 应用掩码,只在 assistant 回答部分计算损失
if loss_mask.sum() > 0:
loss = (loss * loss_mask).sum() / loss_mask.sum()
else:
loss = torch.tensor(0.0).to(args.device)
loss += res.aux_loss
loss = loss / args.accumulation_steps
# 反向传播
scaler.scale(loss).backward()
# 权重更新
if (step + 1) % args.accumulation_steps == 0:
scaler.unscale_(optimizer)
# 关键之处:梯度裁剪只作用于可训练的 `lora_params`
torch.nn.utils.clip_grad_norm_(lora_params, args.grad_clip)
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad(set_to_none=True)
# 打印日志
if step % args.log_interval == 0:
spend_time = time.time() - start_time
print('Epoch:[{}/{}]({}/{}) loss:{:.3f} ...'.format(...))
# 保存权重 (被注释)
# 关键之处:这里会调用 `save_lora` 函数,只保存 LoRA 的权重,而不是整个模型
# if (step + 1) % args.save_interval == 0:
# save_lora(model, f'...')
接下来,我们启动一个 Epoch 的训练进行观察.
# 计算每个 epoch 的迭代次数
iter_per_epoch = len(train_loader) # 结果是 1
# 开始主训练循环
# 由于 `args.epochs` 设置为 1,这个循环只会执行一次
for epoch in range(args.epochs):
# 调用 `train_epoch` 函数,开始 LoRA 微调
train_epoch(epoch)
Epoch:[1/1](0/1) loss:8.992 lr:0.000550000000 epoch_Time:0.0min:
# LoRA 微调演示结束后,删除模型对象以释放 GPU 显存
del model